Attacher des GPU à son cluster
Les GPU (GPU) sont des ressources Cloud utilisées pour le rendu graphique et les calculs parallèles lourds.
NumSpot offre la possibilité de déployer des GPU et de les attacher aux workers de votre cluster et ainsi profiter des avantages des GPU pour vos applicatifs.
- Console
- API
Ce qu'il faut savoir avant d'attacher des GPU à vos clusters
Modèles de GPU
NumSpot fournit différents modèles de GPU pour vos clusters, avec différentes quantités de RAM vidéo (VRAM) :
| Modèle de GPU | VRAM du GPU (en Mio) | Nombre maximum de vCores | Quantité maximum de mémoire (en Gio) | Générations de processeur compatibles | Régions |
|---|---|---|---|---|---|
| nvidia-a100-80 | 80000 | 35 | 256 | v6 | eu-west-2 |
| nvidia-p6 | 16000 | 80 | 512 | v5 | eu-west-2 |
La disponibilité des GPU
Aujourd'hui, nous rencontrons des problèmes au niveau de la disponibilité des GPU sur les différentes zones des régions mise à votre disposition. Il se peut qu'un modèle de GPU ne soit plus disponible sur une zone. Dans ce cas là, veuillez réssayer sur une autre zone.
Création d'un NodePool avec GPU
L'ajout de GPU se fait au niveau de la création d'un NodePool, et donc à deux endroits différents:
- Lors de la création d'un cluster et de son premier NodePool (OpenShift > Créer un cluster > Créer un nodepool)
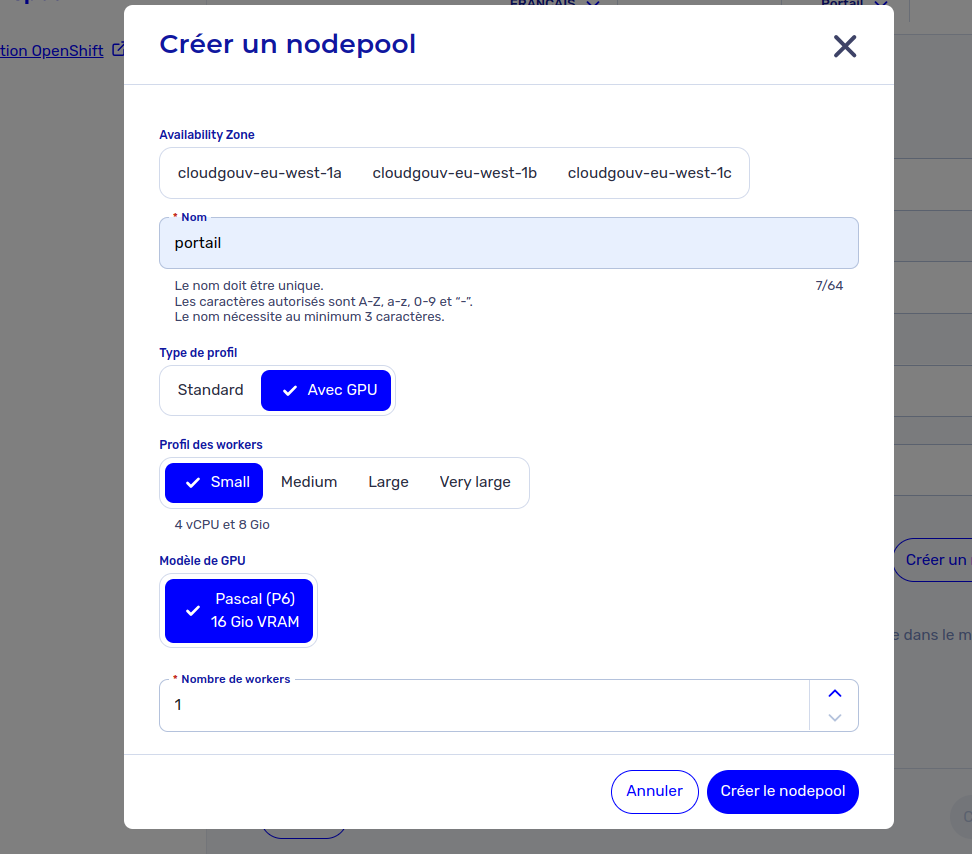
- Lors de l'ajout d'un NodePool à un cluster existant (OpenShift > [clusterID] > Nodepools > Créer)
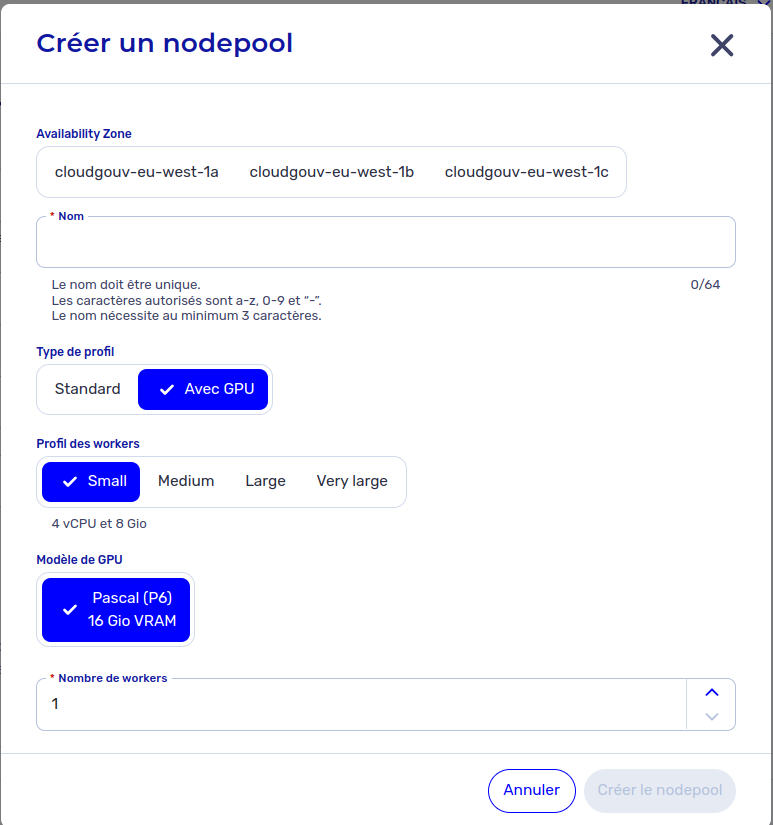
À noter que l'utilisation des GPU dans votre cluster n'est pas possible sur des noeuds ayant le profil "SMALL"
Configuration de votre cluster pour utiliser les GPU
Lorsque vous avez créé votre cluster avec des GPU, il vous reste une dernière étape pour pouvoir les utiliser au sein de votre cluster. Celle-ci consiste à créer une ClusterPolicy
afin de définir les configurations pour l'installation et l'intégration des composants nécessaires pour exploiter les GPU Nvidia déployés sur votre cluster Openshift.
- Console
- API
Avant de procéder, assurez-vous d'avoir vos accès à la console OpenShift avec des droits admin sur le cluster.
Ensuite, suivez les étapes suivantes pour créer la resource ClusterPolicy:
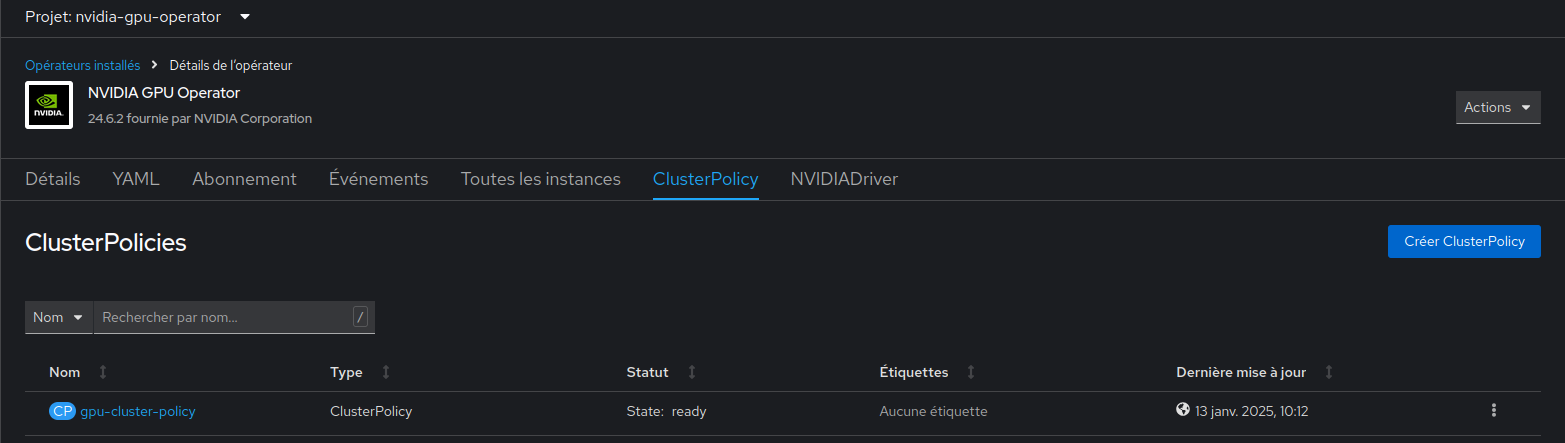
1- Dans le menu latéral, sélectionnez Opérateurs > Opérateurs installés, puis cliquez sur NVIDIA GPU Operator.
2- Sélectionnez l'onglet ClusterPolicy, puis cliquez sur Create ClusterPolicy. La plate-forme attribue le nom par défaut gpu-cluster-policy.
Vous pouvez utiliser cet écran pour personnaliser la ClusterPolicy, mais les valeurs par défaut sont suffisantes pour configurer et faire fonctionner le GPU.
3- Appuyez sur le bouton Create
À ce stade, l'opérateur GPU procède à l'installation de tous les composants requis pour utiliser les GPU NVIDIA dans votre cluster OpenShift. Attendez au moins 10 à 20 minutes avant d'approfondir toute forme de dépannage, car cette opération peut prendre un certain temps.
4- Le statut de la nouvelle ClusterPolicy déployée pour l'opérateur GPU NVIDIA passe à State:ready lorsque l'installation réussit:
Avant de procéder, assurez-vous d'avoir:
- La cli
ocoukubectld'installer - Récupéré le KUBECONFIG de votre cluster
Ensuite, suivez les étapes suivantes pour créer la resource ClusterPolicy:
1- Récupérez la configuration nécessaire à la création de la ressource ClusterPolicy:
export KUBECONFIG=[chemin-vers-votre-kubeconfig]
oc get -n nvidia-gpu-operator $(oc get csv -n nvidia-gpu-operator -l operators.coreos.com/gpu-operator-certified.nvidia-gpu-operator -o name) -o jsonpath={.metadata.annotations.alm-examples} | jq ".[0]" > clusterpolicy.json
2- Appliquez le fichier de configuration pour créer la ressource:
oc apply -f clusterpolicy.json
Vous pouvez utiliser ce fichier contenant la configuration de la ressource ClusterPolicy pour la personnaliser, mais les valeurs par défaut sont suffisantes pour configurer et faire fonctionner le GPU.
À ce stade, l'opérateur GPU procède à l'installation de tous les composants requis pour utiliser les GPU NVIDIA dans votre cluster OpenShiff. Attendez au moins 10 à 20 minutes avant d'approfondir toute forme de dépannage, car cette opération peut prendre un certain temps.
Vous pouvez suivre l'installation des composants en listant les pods dans le namespace "nvidia-gpu-operator":
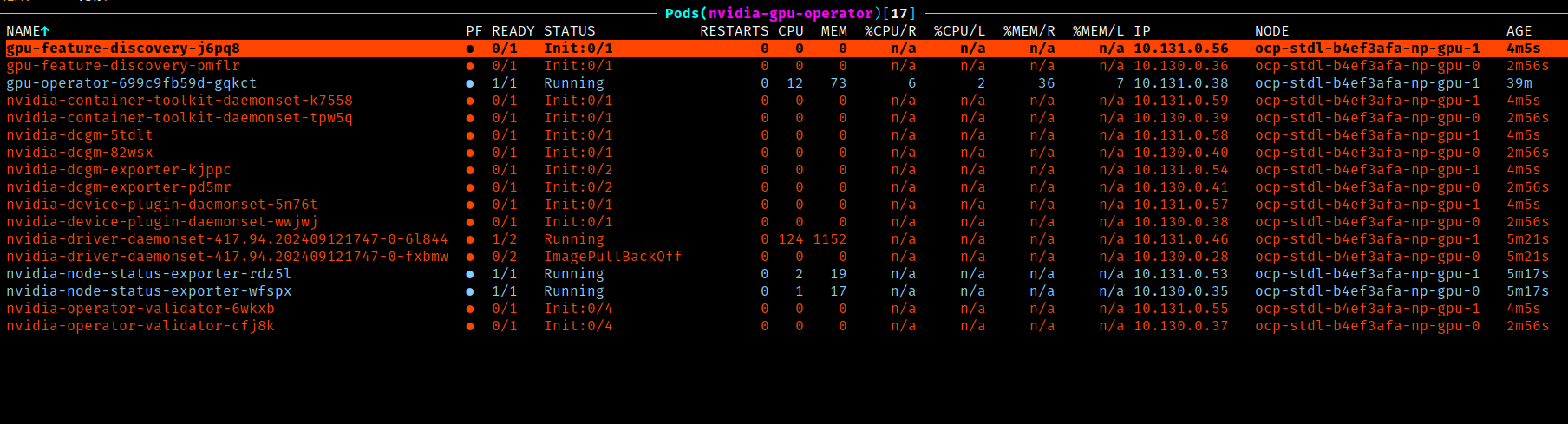
Lorsque tous les pods ci-dessus sont passé à l'état "ready", la ressource `Clusterpolicies" devrait être passè à l'état "ready" également:

Prérequis
- Un compte NumSpot
- Un espace NumSpot auquel le compte est associé
- Un compte avec le rôle
OpenShift Adminsur l'espace - Un jeton de connexion associé au compte NumSpot utilisé
Ce qu'il faut savoir avant d'attacher des GPU à vos clusters
Modèles de GPU
NumSpot fournit différents modèles de GPU pour vos clusters, avec différentes quantités de RAM vidéo (VRAM) :
| Modèle de GPU | VRAM du GPU (en Mio) | Nombre maximum de vCores | Quantité maximum de mémoire (en Gio) | Générations de processeur compatibles | Régions |
|---|---|---|---|---|---|
| nvidia-a100-80 | 80000 | 35 | 256 | v6 | eu-west-2 |
| nvidia-p6 | 16000 | 80 | 512 | v5 | eu-west-2 |
La disponibilité des GPU
Nous rencontrons des limites au niveau de la disponibilité des GPU sur les différentes zones des régions mise à votre disposition. Il se peut qu'un modèle de GPU ne soit plus disponible sur une zone. Dans ce cas là, veuillez réssayer sur une autre zone.
Création d'un NodePool avec GPU
Avant de procéder, assurez-vous d'avoir:
- Un compte NumSpot
- Un espace NumSpot auquel le compte est associé
- Un compte avec le rôle
OpenShift Adminsur l'espace - Un jeton de connexion associé au compte NumSpot utilisé
L'ajout de GPU se fait au niveau de la création d'un NodePool, et donc à deux endroits différents:
- Lors de la création d'un cluster et de son premier NodePool:
export REGION="myregion"
export SPACE_ID="myspaceid"
export ACCESS_TOKEN="myaccesstoken"
curl -X POST https://api.$REGION.numspot.com/openshift/spaces/$SPACE_ID/clusters \
--header "Authorization: Bearer $ACCESS_TOKEN" \
--header "Content-Type: application/json" \
--data '{
"name": "myCluster",
"cidr": "172.1.0.0/16",
"version": "4.17.0",
"nodepools": [
{
"name": "np-gpu-1",
"nodeProfile": "MEDIUM",
"nodeCount": 2,
"availabilityZoneName": "eu-west-2b",
"gpu": "P6"
}
]
}'
- Lors de l'ajout d'un NodePool à un cluster existant (OpenShift > [clusterID] > Nodepools > Créer)
export REGION="myregion"
export SPACE_ID="myspaceid"
export ACCESS_TOKEN="myaccesstoken"
export CLUSTER_ID="myclusterid"
curl -X POST https://api.$REGION.numspot.com/openshift/spaces/$SPACE_ID/clusters/$CLUSTER_ID/nodepools \
--header "Authorization: Bearer $ACCESS_TOKEN" \
--header 'Content-Type: application/json' \
--data '{
"name": "np-gpu-2",
"nodeProfile": "MEDIUM",
"nodeCount": 2,
"availabilityZoneName": "eu-west-2b",
"gpu": "P6"
}'
Si l'opération lancée est validée et acceptée, un objet Operation est retourné par l'API avec un code de statut 201 Created.
Dans le cas où la requête n'a pas été acceptée, une erreur en JSON avec des détails sera renvoyée.
À noter que l'utilisation des GPU dans votre cluster n'est pas possible sur des noeuds ayant le profil "SMALL"
Configuration de votre cluster pour utiliser les GPU
Lorsque vous avez crée votre cluster avec des GPU, il vous restes une dernière étape pour pouvoir les utiliser au sein de votre cluster. Celle-ci consiste à créer une ClusterPolicy
afin de définir les configurations pour l'installation et l'intégration des composants nécessaires pour exploiter les GPU Nvidia déployés sur votre cluster Openshift.
- Console
- API
Avant de procéder, assurez-vous d'avoir vos accès à la console Openshift avec des droits admin sur le cluster.
Ensuite, suivez les étapes suivantes pour créer la resource ClusterPolicy:
1- Dans le menu latéral, sélectionnez Opérateurs > Opérateurs installés, puis cliquez sur NVIDIA GPU Operator.
2- Sélectionnez l'onglet ClusterPolicy, puis cliquez sur Create ClusterPolicy. La plateforme attribue le nom par défaut gpu-cluster-policy.
Vous pouvez utiliser cet écran pour personnaliser la ClusterPolicy, mais les valeurs par défaut sont suffisantes pour configurer et faire fonctionner le GPU.
3- Appuyez sur le bouton Create
À ce stade, l'opérateur GPU procède à l'installation de tous les composants requis pour utiliser les GPU NVIDIA dans votre cluster OpenShift. Cette opération dure généralement entre 10 à 20 minutes.
4- Le statut de la nouvelle ClusterPolicy déployée pour l'opérateur GPU NVIDIA passe à State:ready lorsque l'installation réussit:
Avant de procéder, assurez-vous d'avoir:
- La cli
ocoukubectld'installer - Récupéré le KUBECONFIG de votre cluster
Ensuite, suivez les étapes suivantes pour créer la ressource ClusterPolicy:
1- Récupérez la configuration nécessaire à la création de la ressource ClusterPolicy:
export KUBECONFIG=[chemin-vers-votre-kubeconfig]
oc get -n nvidia-gpu-operator $(oc get csv -n nvidia-gpu-operator -l operators.coreos.com/gpu-operator-certified.nvidia-gpu-operator -o name) -o jsonpath={.metadata.annotations.alm-examples} | jq ".[0]" > clusterpolicy.json
2- Appliquez le fichier de configuration pour créer la ressource:
oc apply -f clusterpolicy.json
Vous pouvez utiliser ce fichier contenant la configuration de la ressource ClusterPolicy pour la personnaliser, mais les valeurs par défaut sont suffisantes pour configurer et faire fonctionner le GPU.
À ce stade, l'opérateur GPU procède à l'installation de tous les composants requis pour utiliser les GPU NVIDIA dans votre cluster OpenShiff. Cette opération dure généralement entre 10 à 20 minutes.
Utilisation des GPU dans votre cluster
Votre cluster est enfin prêt pour utiliser les GPU. Pour ce faire il suffit d'ajouter le bloc suivant dans le manifest de vos applications nécissitant un gpu:
spec:
containers:
- resources:
limits:
nvidia.com/gpu: 1