Démarrage rapide
Prérequis pour suivre ce tutoriel
Afin de profiter des fonctionnalités de gestion de cluster OpenShift depuis la plateforme NumSpot, les prérequis sont:
- Un compte utilisateur NumSpot détenant le rôle
OpenShift Admin. - Ce compte doit être rattaché à un espace NumSpot.
- Avoir un jeton utilisateur (voir comment générer un jeton).
Les interactions avec l'API HTTP de NumSpot nécessitent d'être authentifiées par un jeton d'accès (Access Token) dans une région et un espace donné. Il est donc nécessaire de préparer un environnement d'exécution en conséquence. Cet environnement sera utilisé par les commandes fournies dans ce document.
export REGION="eu-west-2"
export SPACE_ID="myspaceid"
export ACCESS_TOKEN="myaccesstoken"
Il est à noter qu'il est nécessaire de conserver la même session du terminal tout au long de ce tutoriel. Les variables exportées sont disponibles uniquement dans la session dans laquelle elles ont été initialisées, à savoir REGION, SPACE_ID, et ACCESS_TOKEN.
voir la commande ci-dessus où ACCESS_TOKEN est le token obtenu lors de la génération d'un token
Créer mon premier cluster
Pour commencer, nous allons créer un cluster OpenShift en utilisant l'API en HTTP de NumSpot.
Nous utiliserons la région standard (eu-west-2).
Notre premier cluster contiendra un seul Nodepool qui se composera de 2 nodes de type SMALL (associé à des caractéristiques spécifiques), et on l'appelera np1 pour l'identifier.
Pour plus de facilité, nous choisirons la dernière version disponible de l'offre OpenShift de NumSpot que l'on récupère depuis la documentation sur les versions disponibles.
Et enfin, nous utiliserons le CIDR 172.1.1.0/24 ce qui donne la possibilité d'avoir 252 nodes, suffisant dans notre cas (voir: comment choisir le CIDR à la création d'un cluster).
curl -X POST https://api.$REGION.numspot.com/openshift/spaces/$SPACE_ID/clusters \
--header "Authorization: Bearer $ACCESS_TOKEN" \
--header 'Content-Type: application/json' \
--data '{
"name": "my-first-cluster",
"cidr": "172.1.1.0/24",
"version": "4.17.15",
"nodepools": [
{
"name": "np1",
"nodeProfile": "SMALL",
"nodeCount": 2,
}
]
}'
| export OPERATION_ID=$(jq -r .operation.id) && export CLUSTER_ID=$(jq -r .id)
Dans la commande précédente, nous avons utilisé la commande jq pour récupérer:
- L'identifiant de l'
Operationretourné par la requête de création de cluster et le stocker dans la variable d'environnementOPERATION_ID, qui nous servira lorsqu'on voudra suivre l'exécution de la création du cluster, - Le
CLUSTER_IDpour opérer sur le cluster tout juste créé.
La requête retournée donne les informations de l'Operation lancée, à savoir la création d'un cluster.
{
"id": "3fa85f64-5717-4562-b3fc-2c963f66afa6",
"name": "my-first-cluster",
"operation": {
"id": "4784f323-e98d-4d48-bf07-8fc6378a2a07",
"type": "CREATE_CLUSTER",
"status": "PENDING",
"targetLink": "space:8e9cbfeb-573d-4f77-97c2-b7301f38bd2f:cluster:3fa85f64-5717-4562-b3fc-2c963f66afa6",
"selfLink": "https://..../spaces/8e9cbfeb-573d-4f77-97c2-b7301f38bd2f/operations/4784f323-e98d-4d48-bf07-8fc6378a2a07",
...
}
}
Tracer l'Operation de création du cluster en cours
Nous pouvons vérifier notre Operation en exécutant une requête qui récupère les détails de l'Operation effectuée depuis son identifiant (que nous avons stocké plus tôt dans la variable d'environnement OPERATION_ID).
curl -X GET https://api.$REGION.numspot.com/openshift/spaces/$SPACE_ID/operations/$OPERATION_ID \
--header "Authorization: Bearer $ACCESS_TOKEN" \
--header 'Accept: application/json'
{
"id": "4784f323-e98d-4d48-bf07-8fc6378a2a07",
"type": "CREATE_CLUSTER",
"status": "PENDING",
"targetLink": "space:8e9cbfeb-573d-4f77-97c2-b7301f38bd2f:cluster:3fa85f64-5717-4562-b3fc-2c963f66afa6",
"selfLink": "https://..../spaces/8e9cbfeb-573d-4f77-97c2-b7301f38bd2f/operations/4784f323-e98d-4d48-bf07-8fc6378a2a07",
...
}
On peut remarquer que l'Operation contient un type qui indique l'action de l'Operation, et dans notre cas contient le type CREATE_CLUSTER qui indique que l'Operation est une création de cluster OpenShift.
Le status d'une Operation indique l'état d'avancement de celle-ci. Les valeurs possibles sont :
PENDING: l'Operationest en attente d'être exécutée.RUNNING: indique que l'Operationest en cours d’exécution.INTERRUPTED: l'Operationa été interrompue par des processus d'administration de NumSpot et peut être reprise.FAILED: l'Operationa rencontré un problème technique durant l'exécution et s'est terminé.DONE: lorsque l'Operations'est terminée avec succès.
Tant que l'Operation n'est pas terminée (FAILED ou DONE), continuez à surveiller avec cette même requête.
Quand le status devient DONE, félicitations, vous avez enfin votre premier cluster prêt à être utilisé.
Accéder à la console web OpenShift du cluster
Une fois le cluster correctement créé, une console web OpenShift associée au cluster est délivrée. Pour récupérer l'URL, il nous faut lancer une requête pour récupérer les informations du cluster:
curl -X GET https://api.$REGION.numspot.com/openshift/spaces/$SPACE_ID/clusters/$CLUSTER_ID \
--header "Authorization: Bearer $ACCESS_TOKEN" \
--header 'Content-Type: application/json'
Et cela nous retournera les informations du cluster:
{
"id": "3fa85f64-5717-4562-b3fc-2c963f66afa6",
"name": "mycluster",
"cidr": "172.1.0.0/16",
"version": "4.15",
"nodePools": [
{
"name": "np-1",
"nodeProfile": "SMALL",
"nodeCount": 2,
},
{
"name": "np-2",
"nodeProfile": "MEDIUM",
"nodeCount": 1,
"gpu": "P6"
}
],
"urls": {
"console": "string",
"api": "string"
}
}
On retrouve dans le corps de la réponse les champs urls.console et urls.api. Nous utiliserons l'URL urls.console depuis un navigateur. Cette URL permet d'accéder à une page de connexion NumSpot. Une fois connecté, nous serons redirigés vers la console Web d'Openshift.
Les droits d'accès à la console web OpenShift sont basés sur l'IAM NumSpot.
Déployer mon application
Pour utiliser les fonctionnalités du cluster Openshift, un jeton d'authentification est nécessaire pour se connecter au cluster.
Accédez à la console Web d'Openshift, et cliquez sur votre nom de compte situé en haut à droite de la page qui se présente sous la forme d'un menu déroulant :
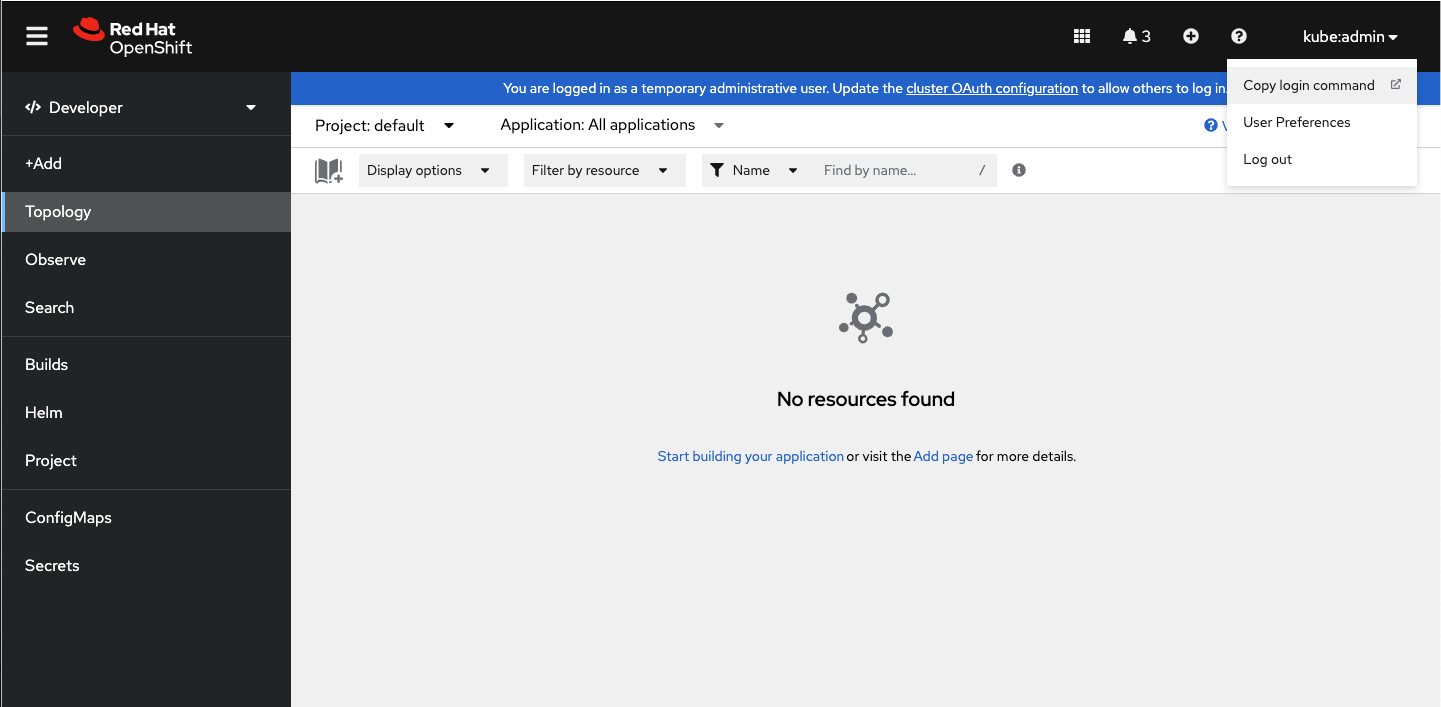
Ensuite cliquez sur Copy login command. Le lien vous redirigera sur une autre page dans laquelle figure le jeton masqué.
Appuyer sur Display Token pour afficher le jeton et obtenir la liste des options possibles de commande pour se connecter au cluster OpenShift :

La commande à retenir pour accéder aux API d'OpenShift est:
oc login --token=[token] --server=[server-url]
Où:
- Le
tokenest un jeton d'API d'authentification valable uniquement 24 heures. - Le
server-urlcorrespond à l'url du cluster Openshift.
La réponse retournée indique le nombre de projets auquel l'utilisateur connecté a droit d'accéder :
You have access to X projects, the list has been suppressed. You can list all projects with 'oc projects'
Le jeton d'API généré par la console Web d'OpenShift a une durée de vie de 24 heures.
Créer mon premier déploiement en ligne de commande
Nous sommes directement dans un projet par défaut.
Une fois connecté via la ligne de commande oc, nous allons pouvoir déployer notre première application.
Créer un fichier deployments.yaml dans lequel vous collez le contenu suivant.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
selector:
matchLabels:
app: nginx
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.27.0
ports:
- containerPort: 80
Ensuite pour déployer cette ressource, il suffit d’exécuter:
oc create deployment -f deployments.yaml
La demande de création de déploiement a été validée et est en train d'être exécutée par Openshift.
Nous allons vérifier que le pod correspondant au déploiement est fonctionnel. Pour cela, il est nécessaire de connaître l'état du pod (readynessProbe et livenessProbe) depuis la ligne de commande suivante:
oc get pods -l app=nginx
Vérifions que le pod du déploiement Nginx est correctement déployé et fonctionnel. Ceci s'effectue par le positionnement des livenessProbe (nombre de droite de l'exécution en cours du conteneur) et readynessProbe (nombre de gauche permettant de savoir si le conteneur est prêt à servir des requêtes) au sein du conteneur qui est représenté par le nombre effectif sous le libellé READY :
# Montrer les lignes des pods en running
NAME READY STATUS RESTARTS AGE
nginx-56d947767c-2948z 1/1 Running 0 2d11h
Voilà, votre première application est correctement déployée et prête à recevoir des requêtes.
Créer un volume persistant et l'attacher à votre application
Une fois votre application crée, il est possible de lui attacher un volume, en suivant la procédure suivante:
1- Créer un PersistentVolumeClaim: créer un fichier pvc.yaml avec le contenu suivant:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
storageClassName: outscale-bsu-standard
Concernant le champ storageClassName, utiliser les storageClasses mise à disposition dans votre cluster. Vous pouvez les lister via la commande oc get storageclasses
Une storage class est défini pour chaque type de volume.
Pour déployer cette ressource, il suffit d'exécuter:
oc apply -f pvc.yaml
La demande de création de la ressource PersistentVolumeClaim (PVC) a été validée et créée. En revanche, le volume en mode bloc correspondant (PersistentVolume) n'a pas encore été créé. En effet, nos storageClasses sont configurées pour attendre le premier consommateur avant de créer le volume associé au PVC.
Ainsi, il faut configurer votre application pour utiliser le PVC. Cela se fait dans le déploiement de l'application, en éditant le fichier deployments.yaml de la manière suivante:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
selector:
matchLabels:
app: nginx
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.27.0
ports:
- containerPort: 80
volumes:
- name: storage
persistentVolumeClaim:
claimName: my-pvc
On ajoute au déploiement une partie "volume" dans le yaml, et on y retrouve la référence au PVC défini plus haut my-pvc.
Ensuite pour appliquer cette modification sur la ressource Deployment, il suffit d’exécuter:
oc apply -f deployments.yaml
Si tout se passe bien, un PersistentVolume devrait être créé.
Pour vérifier, lancer la commande oc get pv et vous devriez voir votre PersistentVolume, celui-ci correspond à un volume en mode bloc créé à la demande par le CSI.
À noter:
- Vous ne pouvez migrer votre application sur une autre zone si celle-ci est lié à un volume car l'application doit être dans la même zone que le volume.
- Si vous supprimez votre cluster, les volumes en mode bloc ne seront pas supprimés automatiquement. Vous devez supprimer les ressources PersistentVolume avant de supprimer votre cluster.
Augmenter le nombre de nodes d'un Nodepool
Initialement, nous avons un Nodepool qui contient seulement 2 nodes et nous allons le modifier pour en avoir 4, donc 2 supplémentaires.
Rappelons-nous que nous avons nommé le premier Nodepool np1.
curl -X POST https://api.$REGION.numspot.com/openshift/spaces/$SPACE_ID/clusters/nodepools/np1 \
--header "Authorization: Bearer $ACCESS_TOKEN" \
--header 'Content-Type: application/json' \
--data '{
"nodeCount": 4
}'
La requête renvoie les informations de l'Operation lancée.
{
"clusterId": "3fa85f64-5717-4562-b3fc-2c963f66afa6",
"nodePoolName": "np1",
"operation": {
"id": "680d2446-dc82-4a98-8b6b-71f3f982acaa",
"type": "UPDATE_WORKER_NODES",
"status": "PENDING",
"targetLink": "space:8e9cbfeb-573d-4f77-97c2-b7301f38bd2f:cluster:3fa85f64-5717-4562-b3fc-2c963f66afa6",
"selfLink": "https://..../spaces/8e9cbfeb-573d-4f77-97c2-b7301f38bd2f/operations/680d2446-dc82-4a98-8b6b-71f3f982acaa",
...
}
}
Pour rappel, on peut suivre la bonne exécution de l'Operation d'ajout de nodes dans un nodepool à partir de l'API :
curl -X GET /openshift/spaces/$SPACE_ID/operations/$OPERATION_ID \
--header "Authorization: Bearer $ACCESS_TOKEN" \
--header 'Accept: application/json'
Créer un Nodepool avec GPU
Dans le cas où l'application a besoin d'une puissance de calcul graphique (pour des besoins en IA par exemple), nous devons disposer d'un node pouvant utiliser de la ressource graphique (GPU).
Utiliser la méthode précédente pour éditer la présence de GPU n'est pas possible. Nous devons alors créer un second Nodepool qui lui, contiendra de la ressource GPU. Nous allons utiliser la ressource GPU appelée NVIDIA P6 (Pascal), disponible dans toutes les régions.
En savoir plus sur les GPUs disponibles
curl -X POST https://api.$REGION.numspot.com/openshift/spaces/$SPACE_ID/clusters/nodepools \
--header "Authorization: Bearer $ACCESS_TOKEN" \
--header 'Content-Type: application/json' \
--data '{
"name": "np-gpu1",
"nodeCount": 4,
"nodeProfile": "SMALL",
"gpu": "P6"
}'
La requête renvoie les informations de l'Operation lancée.
{
"clusterId": "3fa85f64-5717-4562-b3fc-2c963f66afa6",
"nodePoolName": "np-gpu1",
"operation": {
"id": "6fb436c4-0bda-4dda-84f6-210425ba79e8",
"type": "UPDATE_WORKER_NODES",
"status": "PENDING",
"targetLink": "space:8e9cbfeb-573d-4f77-97c2-b7301f38bd2f:cluster:3fa85f64-5717-4562-b3fc-2c963f66afa6",
"selfLink": "https://..../spaces/8e9cbfeb-573d-4f77-97c2-b7301f38bd2f/operations/6fb436c4-0bda-4dda-84f6-210425ba79e8",
...
}
}
Surveiller son cluster
Pour surveiller son propre cluster OpenShift, il convient juste de se logger et d'observer toutes les informations qui sont récoltées dans la page d'accueil que voici :